Redis 的底层数据结构
下面主要介绍 SDS 和 跳跃表
1、Redis 字符串(String)
我们可以使用 object encoding key 可以显示类型的底层数据结构

图1
从 图1 中我们可以看出, String 数据类型的数据结构有 embstr 以及 int。虽然 Redis 是用 C 语言写的,但是不是用 C 语言的字符串(即以空字符’\0’结尾的字符数组),而是自定义的简单动态字符串(simple dynamic string,SDS)

用 SDS 保存字符串 “Redis” 的数据结构:
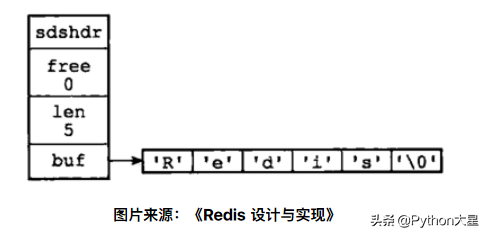
SDS的数据结构
面试中曾经被问到:为什么不用 C 语言的字符串,而是 SDS???
① 由于 SDS 保存了 len 信息,在时间复杂度上优于原生字符串;
② SDS 被称作动态字符串,这和 Java 的 ArrayList 类似,扩容机制如下:
当字符串 len 小于 1M 时,扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间。(字符串最大长度为 512M,另外有 1 个字节用来保存空字符串 '\0'),有效避免了 C 语言缓冲区溢出的现象,同时减少了内存分配的次数。
③ 二进制安全。因为 C 字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此 C 字符串无法正确存取。而 SDS 的 API 都是以处理二进制的方式来处理 buf 里面的元素,并且 SDS 不是以空字符串来判断是否结束,而是以 len 属性表示的长度来判断字符串是否结束。

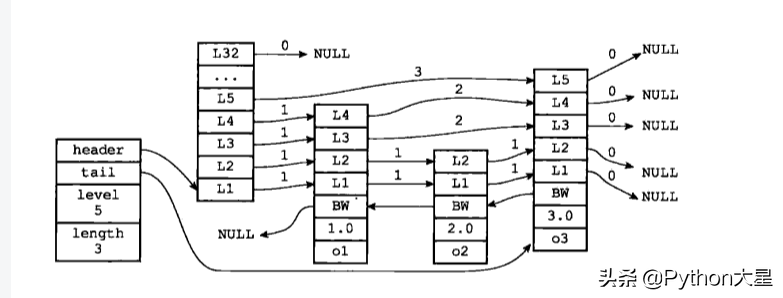
2、跳跃表
Redis 在实现有序集合的时候用到跳跃表,由 redis.h/zskiplistNode 和 redis.h/zskiplist 两个结构定义,其中 zskiplistNode 结构用于表示跳跃表节点,而 zskiplist 结构则用于保存跳跃表节点的相关信息,比如节点的数量,以及指向表头节点和表尾节点的指针等等。

Redis 的 qps
qps (Queries Per Second ),每秒能处理查询数目。
官方提供的数据是可以达到 100000 + 的 QPS(每秒内查询次数)。
关于你生产环境的 qps,评论下你倒是留言说啊!
如何测试 Redis 的 qps?
Redis 做压测可以用自带的 redis-benchmark
Redis 性能压测工具的具体参数:

压测 get 命令,并发 50,连接数 1 w(单台 Redis)
1、测试 get 命令
redis-benchmark -h 127.0.0.1 -p 6086 -c 50 -n 10000 -t get

2、测试 set 命令
redis-benchmark -h 127.0.0.1 -p 6086 -c 50 -n 10000 -t set

3、查看所有命令
redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000 -q

Redis 集群
集群:通过增加服务器的数量,提供相同的服务,从而让服务器达到一个稳定、高效的状态。
说着怎么像增加了一个备胎。
1、Redis 主从复制
主从复制是主机数据更新后根据配置和策略,自动同步到备机的 master/slaver 机制,master 以写为主,slaver 只可读。用于可穿透业务场景,如后端有 DB 存储,脱机影响不大的应用。
① 主从复制原理
分 2 个阶段
服务器初始化阶段:
slaver 连接主服务器,发送 sync 命令;
master 连接收到 sync 命名后,执行 bgsave 命令生成 rdb 文件并使用缓冲区记录伺候执行的所有写命令;
master bgsave 完成后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
slaver 收到 快照,丢弃旧数据,载入收到的快照;
master 快照发送完毕开始向从服务器发送缓冲区的写命令;
从服务器完成快照的载入,开始接收命令请求,并执行来自 master 缓冲区的写命令
服务器初始化完成阶段:
master 每执行一个写命令就会向从服务器发送相同的写命令,slaver 接收并执行收到的写命令
② 主从复制的优缺点
优点:进行读写分离;缺点:不具备自动容错和恢复功能,需要手动切换。
2、sentinel (哨兵)
上面主从复制,如果 master 挂了,后果严重。
Redis 2.8 中提供了哨兵工具来实现自动化的系统监控和故障恢复功能。用于高可用需求场景,可用于高可用 Cache, 存储等场景。 内存 / QPS 受限于单机。
① 哨兵的作用:
a.监控(Monitoring)
不断地检查 redis 的主服务器和从服务器是否运作正常
b.提醒(Notification)
如果发现某个 redis 服务器运行出现状况,可以通过 API 向管理员或者其他应用程序发送通知
c.自动故障迁移(Automatic failover)
能够进行自动切换。当一个主服务器不能正常工作时,会将 失效 master 的其中一个 slaver 升级为 新的 master,并让 失效 master 的其他 slaver 改为复制新的 master; 当客户端试图连接失效的 master 时, 集群也会向客户端返回 新 master 的地址, 使得集群可以使用 新 master 代替失效服务器。
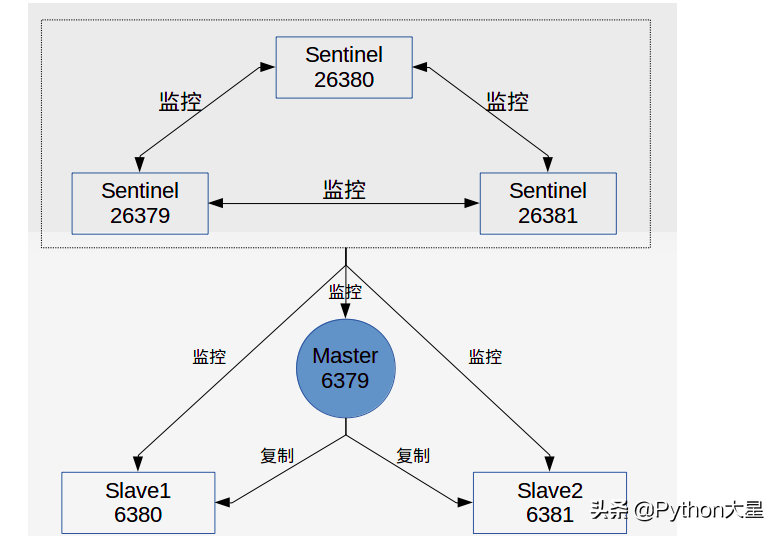
② sentinel (哨兵)的优缺点
优点:具备主从复制的优点,具备容错和恢复功能。
缺点:每台 redis 服务器都存储相同的数据,浪费内存。
3、Redis Cluster
Redis 从 3.0 开始支持 Cluster 集群功能,实现的 redis 的分布式存储,也就是说每台 redis 节点上存储不同的内容。用于高可用需求场景,可用于大数据量高可用 Cache / 存储等场景。 内存 / QPS 不受限于单机,可受益于分布式集群高扩展性。
Redis Cluster 原理
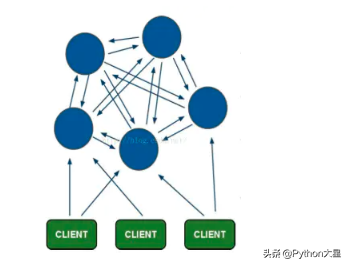
- 所有的 redis 节点彼此互联 (PING-PONG 机制),节点的 fail 是通过集群中【超过半数】的节点检测失效时才生效。
- 客户端与 redis 节点【直连】,不需要中间 proxy 层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
- redis-cluster 把所有的物理节点映射到 [0-16383] slot 上(不一定是平均分配),cluster 负责维护 node<->slot<->value。
- Redis 集群预分好 16384 个桶,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16 (key) mod 16384 的值,决定将一个 key 放到哪个桶中。
Redis 中的 big key 和 hot key 问题
1、big key
在 Redis 字符串类型的 Value 最多可以容纳的数据长度是 512M。阿里云 Redis 规范中,我们看一看怎么说的。
在 Redis Cluster 集群中,如果某台机器因 big key 造成内存不足,会拖累整个集群的使用。
比如:
微博盖楼评论,群聊天记录等
如何解决 big key 问题:
比如对一个大的 json 字符串可以使用 Mset 命令用于同时设置一个或多个 key-value 对。
redis 127.0.0.1:6379> MSET key1 value1 key2 value2 .. keyN valueN
将这个 key 的内容打散到各个实例中,减小 big key 对数据量倾斜造成的影响。
2、hot key
热点 key 问题容易导致缓存击穿。如一些热点新闻,商品秒杀场景中。
解决思路:
① 使用客户端本地缓存,需要考虑 2 个问题:客户端的本地缓存是否会过大,影响本身缓存开销;如何保证本地缓存和 redis 集群数据的有效期的一致性
② 将 hot key 分散处理
根据集群机器个数,将 hot key 加上前缀或者后缀,使其分散访问。
Redis 缓存的高时效性问题
如果项目需求对缓存有一定时效性要求,一般处理逻辑是在数据变化,缓存也跟着变化。
无论是先删除缓存,还是后删除缓存,由于非原子操作,会出现 Redis 和 Mysql 双写不一致的情况。
1、延时双删策略
- 先淘汰缓存
- 再写数据库
- 休眠 1 秒,再次淘汰缓存
2、重试机制

- 更新数据库数据
- 缓存删除失败
- 将需要删除的 key 发送至消息队列
- 自己消费消息,获得需要删除的 key
- 继续重试删除操作,直到成功
Redis 缓存雪崩、缓存穿透和缓存击穿问题
1、缓存雪崩
缓存雪崩是指在设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,导致所有的查询都落在数据库上,造成了缓存雪崩。
解决方案:
① 不同的 key 的失效时间加上随机值,避免同一时间失效
② 设置本地缓存+限流
2、缓存穿透
缓存穿透是指查询一个一定不存在的数据,而用户不断发起请求。
解决方案:
① 接口层增加校验
比如用户鉴权校验,参数做校验,不合法的参数直接代码 Return,比如:id 做基础校验,id <=0 的直接拦截等。
② 当我们从数据库找不到的时候,我们也将这个空对象设置到缓存里边去。下次再请求的时候,就可以从缓存里边获取了。
③ 运维对单个 IP 每秒访问次数超出阈值的 IP 都拉入黑名单
④ 【布隆过滤器】,利用高效的数据结构和算法快速判断出你这个 Key 是否在数据库中存在,不存在你 return 就好了,存在你就去查了 DB 刷新 KV 再 return
3、缓存击穿
热点 key 问题
解决方案:
① 设置永不过期
② 互斥锁
只让一个线程构建缓存,其他线程等待构建缓存的线程执行完,重新从缓存获取数据。
③ 热点资源隔离