- 原文地址:Send HTTP Requests As Fast As Possible in Python
- 原文作者:Andrew Zhu
- 译文出自:掘金翻译计划
- 本文永久链接:https://github.com/xitu/gold-miner/blob/master/article/2021/send-http-requests-as-fast-as-possible-in-python.md
- 译者:ItzMiracleOwO
- 校对者:jaredliw、KimYangOfCat
代码在云端的带有 Python 3.7 的 Linux(Ubuntu) VM 主机中运行。所有都代码存放在 Gist 中,都可以复制和运行。
方法 #1 : 使用同步
这是最简单易懂的方式,但也是最慢的方式。我通过这个神奇的 Python 列表操作符为测试伪造了 100 个链接:
url_list = ["https://www.google.com/","https://www.bing.com"]*50
代码:
import requests
import time
def download_link(url:str) -> None:
result = requests.get(url).content
print(f'Read {len(result)} from {url}')
def download_all(urls:list) -> None:
for url in urls:
download_link(url)
url_list = ["https://www.google.com/","https://www.bing.com"]*50
start = time.time()
download_all(url_list)
end = time.time()
print(f'download {len(url_list)} links in {end - start} seconds')
它用了十秒钟来完成下载 100 个链接。
...
download 100 links in 9.438416004180908 seconds
作为一个同步的解决方案,这个代码仍有改进的空间。我们可以利用 Session 对象来提高速度。Session 对象将使用 urllib3 的连接池,这意味着对于对同一主机的重复请求,将重新使用 Session 对象的底层 TCP 连接,从而获得性能提升。
因此,如果您向同一主机发出多个请求,则底层 TCP 连接将被重用,这可能会导致性能显著提升 —— Session 对象
为了确保请求对象无论成功与否都退出,我将使用 with 语句作为上下文管理器。Python 中的 with 关键词只是替换 try…… finally…… 的一个干净的解决方案。
让我们看看将代码改成这样可以节省多少秒:
import requests
from requests.sessions import Session
import time
url_list = ["https://www.google.com/","https://www.bing.com"]*50
def download_link(url:str,session:Session):
with session.get(url) as response:
result = response.content
print(f'Read {len(result)} from {url}')
def download_all(urls:list):
with requests.Session() as session:
for url in urls:
download_link(url,session=session)
start = time.time()
download_all(url_list)
end = time.time()
print(f'download {len(url_list)} links in {end - start} seconds')
看起来性能真的提升到了 5.x 秒。
...
download 100 links in 5.367443561553955 seconds
但是这样还是很慢,让我们试试多线程的解决方案。
解决方案#2:多线程方法
Python 线程是一个危险的话题,有时,多线程可能会更慢!戴维·比兹利(David Beazley)带来了一场精彩的、涵盖了这个危险的话题的演讲。YouTube 链接在这里。
无论如何,我仍然会使用 Python 线程来完成 HTTP 请求工作。我将使用一个队列来保存 100 个链接并创建 10 个 HTTP 工作线程来异步下载这 100 个链接。

要使用 Session 对象,为 10 个线程创建 10 个 Session 对象是一种浪费,我只想要创建一个 Session 对象并在所有下载工作中重用它。为了实现这一点,代码将利用 threading 包中的 local 对象,这样 10 个线程工作将共享一个 Session 对象。
from threading import Thread,local
...
thread_local = local()
...
代码:
import requests
from requests.sessions import Session
import time
from threading import Thread,local
from queue import Queue
url_list = ["https://www.google.com/","https://www.bing.com"]*50
q = Queue(maxsize=0) #Use a queue to store all URLs
for url in url_list:
q.put(url)
thread_local = local() #The thread_local will hold a Session object
def get_session() -> Session:
if not hasattr(thread_local,'session'):
thread_local.session = requests.Session() # Create a new Session if not exists
return thread_local.session
def download_link() -> None:
'''download link worker, get URL from queue until no url left in the queue'''
session = get_session()
while True:
url = q.get()
with session.get(url) as response:
print(f'Read {len(response.content)} from {url}')
q.task_done() # tell the queue, this url downloading work is done
def download_all(urls) -> None:
'''Start 10 threads, each thread as a wrapper of downloader'''
thread_num = 10
for i in range(thread_num):
t_worker = Thread(target=download_link)
t_worker.start()
q.join() # main thread wait until all url finished downloading
print("start work")
start = time.time()
download_all(url_list)
end = time.time()
print(f'download {len(url_list)} links in {end - start} seconds')
结果:
...
download 100 links in 1.1333789825439453 seconds
下载的速度非常快!比同步解决方案快得多。
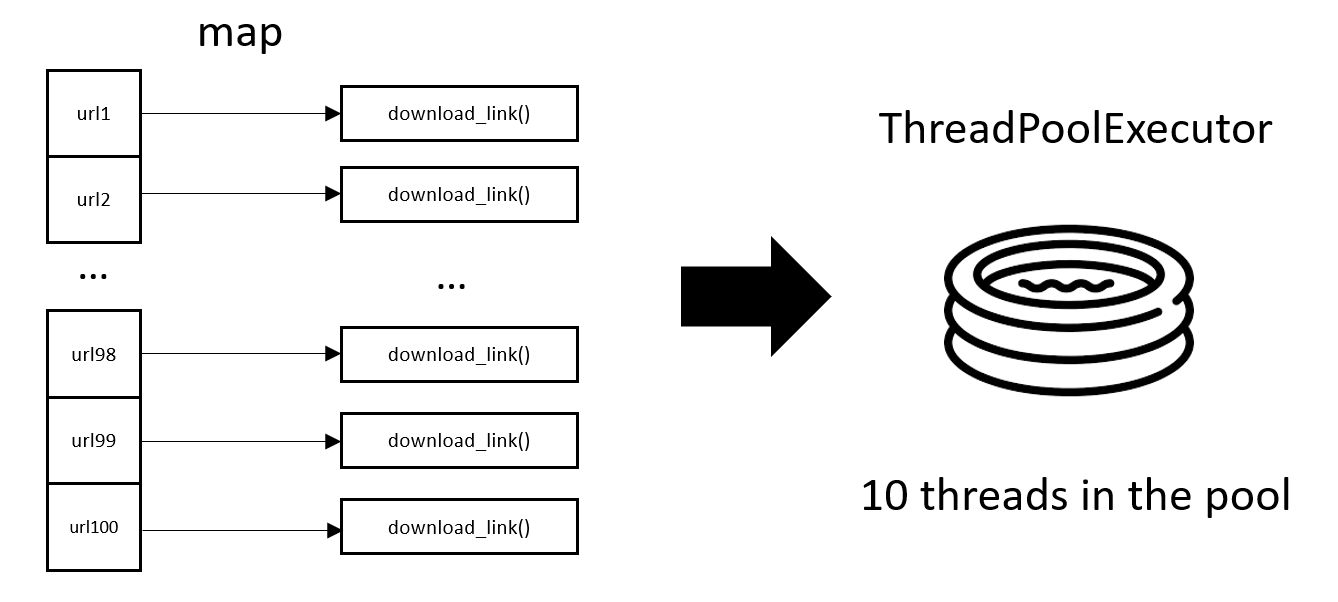
解决方案 #3:通过 ThreadPoolExecutor 进行多线程
Python 还提供了 ThreadPoolExecutor 来执行多线程工作,我很喜欢 ThreadPoolExecutor。
在 Thread + Queue 的版本中,HTTP 请求工作中有一个 while True 循环,这使得 worker 函数与 Queue 纠缠不清,从同步版本变更到异步版本的代码需要额外的改动。
有了 ThreadPoolExecutor 及其 map 函数,我们可以创建一个代码非常简洁的多线程版本,只需要从同步版本中进行很小的代码更改。
代码:
import requests
from requests.sessions import Session
import time
from concurrent.futures import ThreadPoolExecutor
from threading import Thread,local
url_list = ["https://www.google.com/","https://www.bing.com"]*50
thread_local = local()
def get_session() -> Session:
if not hasattr(thread_local,'session'):
thread_local.session = requests.Session()
return thread_local.session
def download_link(url:str):
session = get_session()
with session.get(url) as response:
print(f'Read {len(response.content)} from {url}')
def download_all(urls:list) -> None:
with ThreadPoolExecutor(max_workers=10) as executor:
executor.map(download_link,url_list)
start = time.time()
download_all(url_list)
end = time.time()
print(f'download {len(url_list)} links in {end - start} seconds')
最后的输出和线程队列版本一样快:
...
download 100 links in 1.0798051357269287 seconds
解决方案 #4:asyncio 与 aiohttp
每个人都说 asyncio 就是未来,而且速度很快。有些人使用它 来用 Python 的 asyncio 和 aiohttp 包发出 100 万次 HTTP 请求。尽管 asyncio 非常快,但它没有使用 Python 多线程。
你敢相信吗,asyncio 只有在一个线程、一个 CPU 核心中运行!
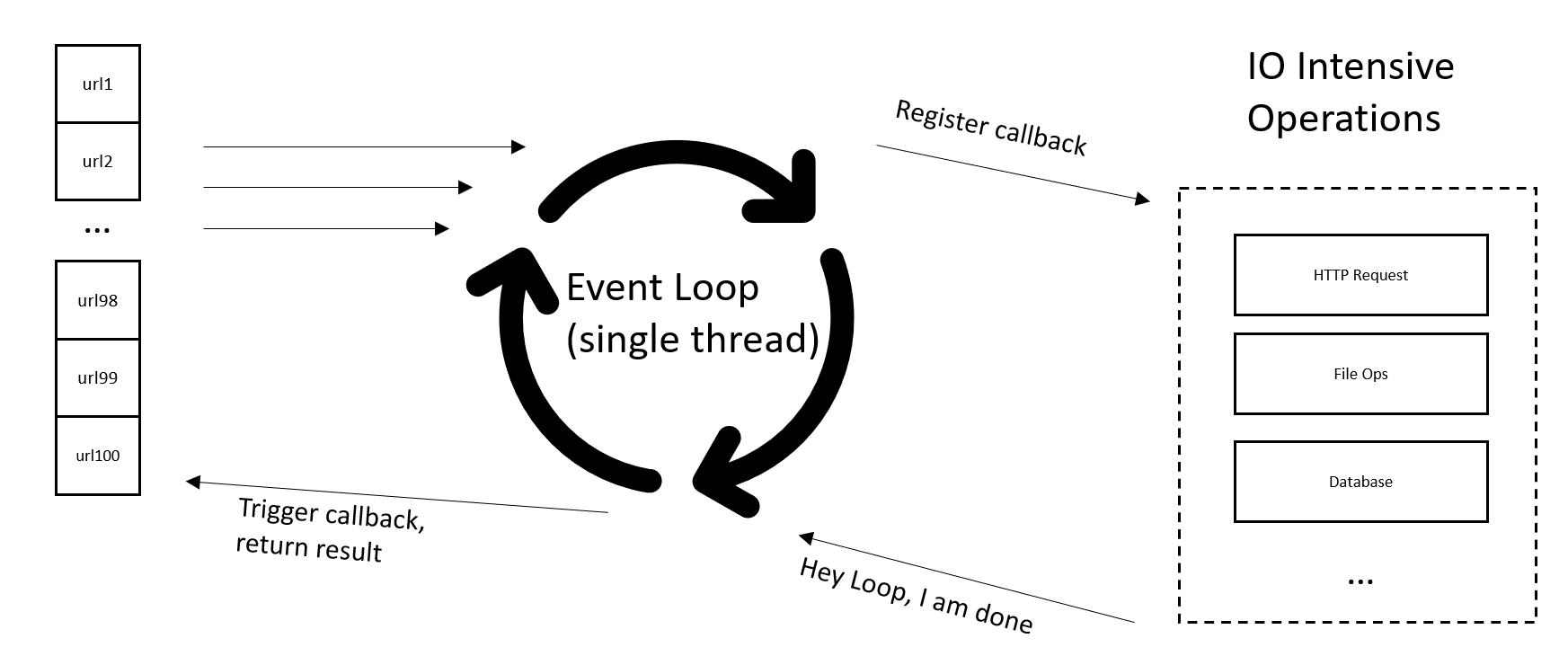
在 asyncio 中实现的事件循环几乎与 Javascript 中使用的相同。
Asyncio 非常快,几乎可以向服务器发送任意数量的请求,唯一的限制是您的设备和互联网带宽。
发送过多的 HTTP 请求会表现得像“攻击”。当检测到太多请求时,某些网站可能会封锁您的 IP 地址,甚至 Google 也会封锁您。为了避免被封锁,我使用了一个自定义 TCP 连接器对象,
该对象将最大 TCP 连接数指定为 10。(将其更改为 20 应该也是安全的。)
my_conn = aiohttp.TCPConnector(limit=10)
这个代码非常简短:
import asyncio
import time
import aiohttp
from aiohttp.client import ClientSession
async def download_link(url:str,session:ClientSession):
async with session.get(url) as response:
result = await response.text()
print(f'Read {len(result)} from {url}')
async def download_all(urls:list):
my_conn = aiohttp.TCPConnector(limit=10)
async with aiohttp.ClientSession(connector=my_conn) as session:
tasks = []
for url in urls:
task = asyncio.ensure_future(download_link(url=url,session=session))
tasks.append(task)
await asyncio.gather(*tasks,return_exceptions=True) # the await must be nest inside of the session
url_list = ["https://www.google.com","https://www.bing.com"]*50
print(url_list)
start = time.time()
asyncio.run(download_all(url_list))
end = time.time()
print(f'download {len(url_list)} links in {end - start} seconds')
上面的代码在 0.74 秒内完成了 100 个链接的下载!
...
download 100 links in 0.7412574291229248 seconds
请注意,如果您想在 Jupyter Notebook 或 IPython 中运行代码,请安装 nest-asyncio 包。 (感谢这个 StackOverflow 链接。感谢 Diaf Badreddine。)
pip install nest-asyncio
并在代码开头添加以下两行代码:
import nest_asyncio
nest_asyncio.apply()
解决方案#5:如果是 Node.js 呢?
我想知道,如果我在具有内置事件循环的 Node.js 中做同样的工作会怎样?
这是完整的代码。
const requst = require('request')
//build a 100 links array
url_list = []
url_list.push(...Array(50).fill("https://www.google.com"))
url_list.push(...Array(50).fill("https://www.bing.com"))
const batch_num = 10; // send 10 Http requesta at one time
let batch_index = batch_num;
let resolvehandler = null;
function download_link(url){
requst({
url: url,
timeout:1000
},function(error,response,body){
if (body){
console.log(body.length)
}
batch_index = batch_index -1
if(batch_index==0){
batch_index = batch_num
resolvehandler()
}
});
}
function download_batch(url_list){
for(j = 0;j<batch_num;j++){
download_link(url_list[j])
}
}
async function download_all(url_list){
let loop_count = url_list.length/batch_num;
console.time('test')
for(var i =0;i<loop_count;i++){
await new Promise(function(resolve,reject){
download_batch(url_list.slice(i,i+10))
resolvehandler = resolve
})
}
console.timeEnd('test')
}
download_all(url_list)
这个代码需要 1.1 到 1.5 秒,您可以运行它在您的设备中查看结果。
...
test: 1195.290ms
Python 赢得了这场速度的游戏!
(看起来 Node.js 的 request 包已经被弃用了,但这个示例只是为了测试 Node.js 的事件循环与 Python 的事件循环相比如何执行。)